Audio Fingerprinting and Recognition System
Degree:
Audio Fingerprinting and Recognition System
Course:
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The purpose of the project is to simulate the behavior of the popular mobile application Shazam© [1]. This involves the analysis and implementation of a system for the recognition of music, starting from low quality audio clips (smartphone) and in the presence of background noise.
The recognition is based on the Fingerprint. Generally speaking, a fingerprint, or "footprint digital audio", is a compact signature, deterministic and based on the content that summarizes an audio piece. This signature is often used to identify and describe a piece of audio.
In short, the necessary procedures for the determination of this signature are:
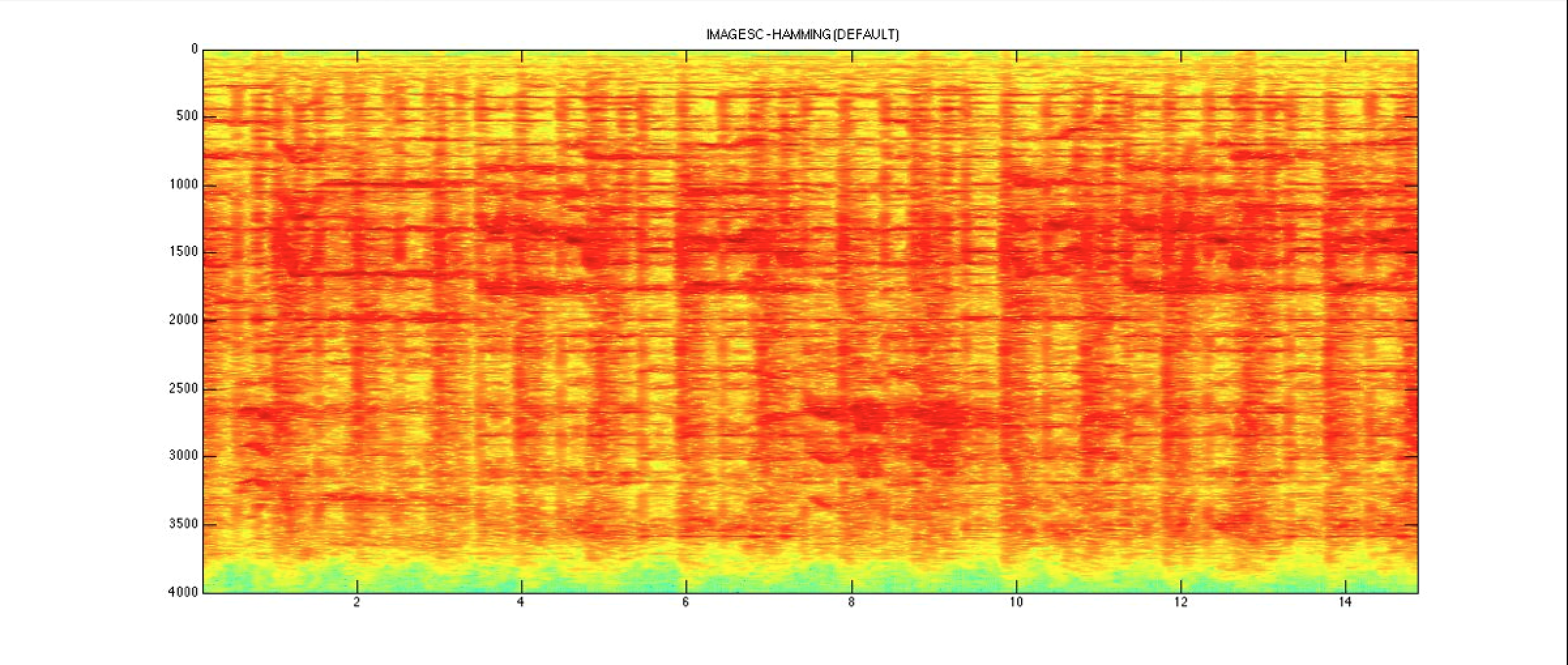
- calculation of the spectrogram (square modulus of the intensity of the transform coefficients) [Fig.01];
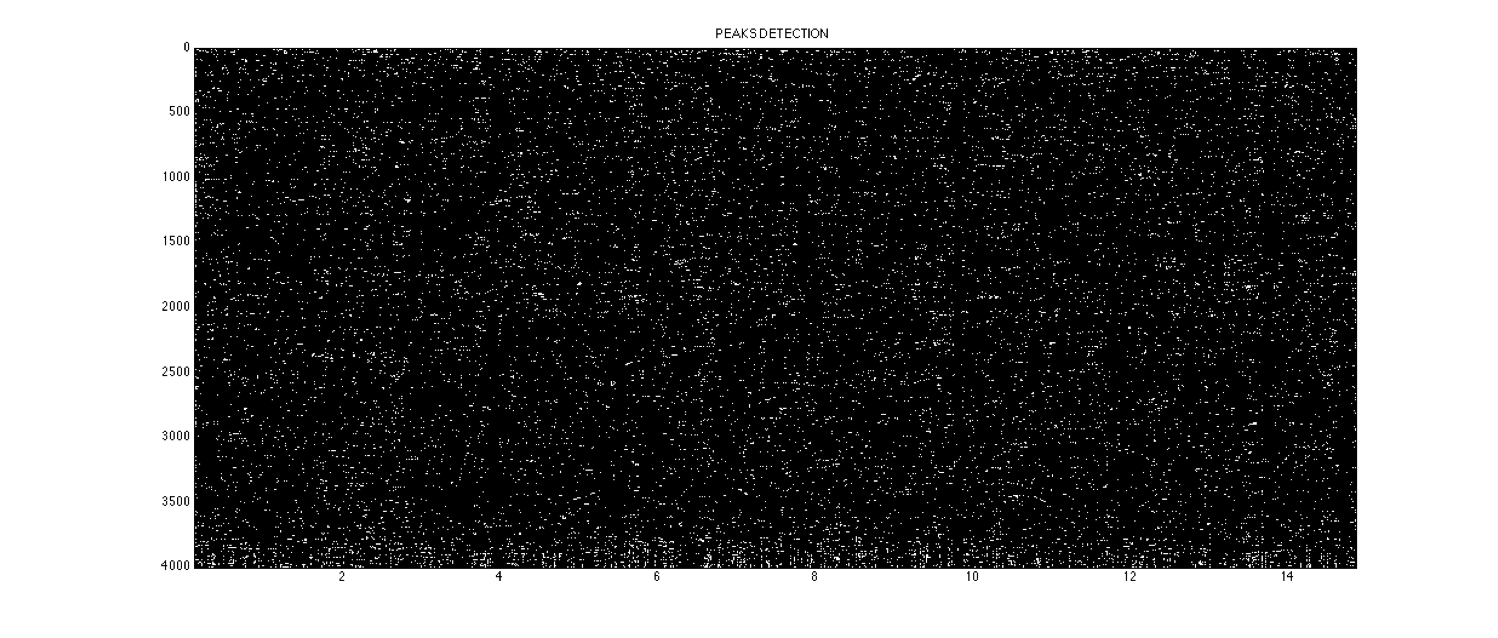
- determination of the maximum points of the spectrogram, locally looking to the larger points of modules [Fig.03]
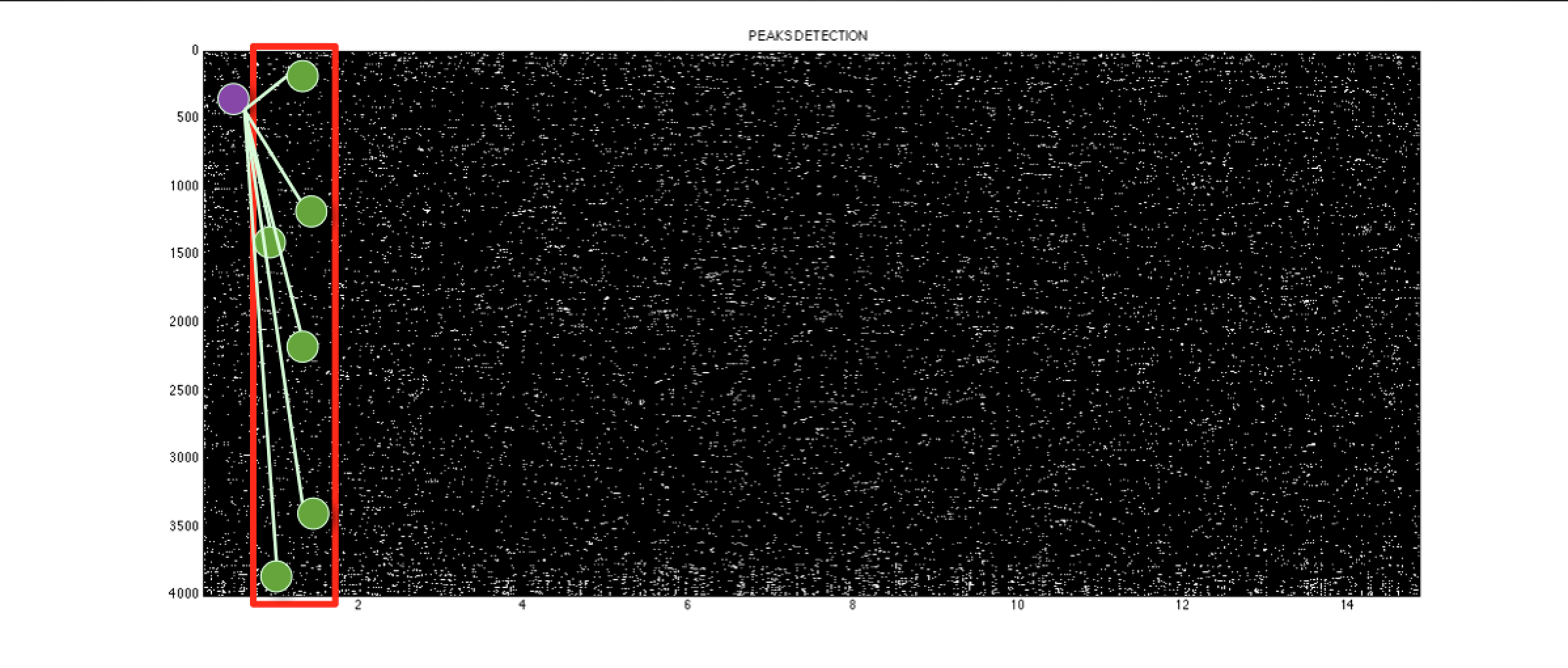
- selection, in a region of half a second (called slots), the most relevant peaks, called Anchor Point (9 points every half second) [Fig.04];
- for each Anchor Point is defined a Target Zone, an area of research that starts from the Anchor Point itself and ends half second after [Fig.05];
- in the region thus defined is searched for the most relevant peaks, called Nearby Peak (other 9 points) [Fig.05];
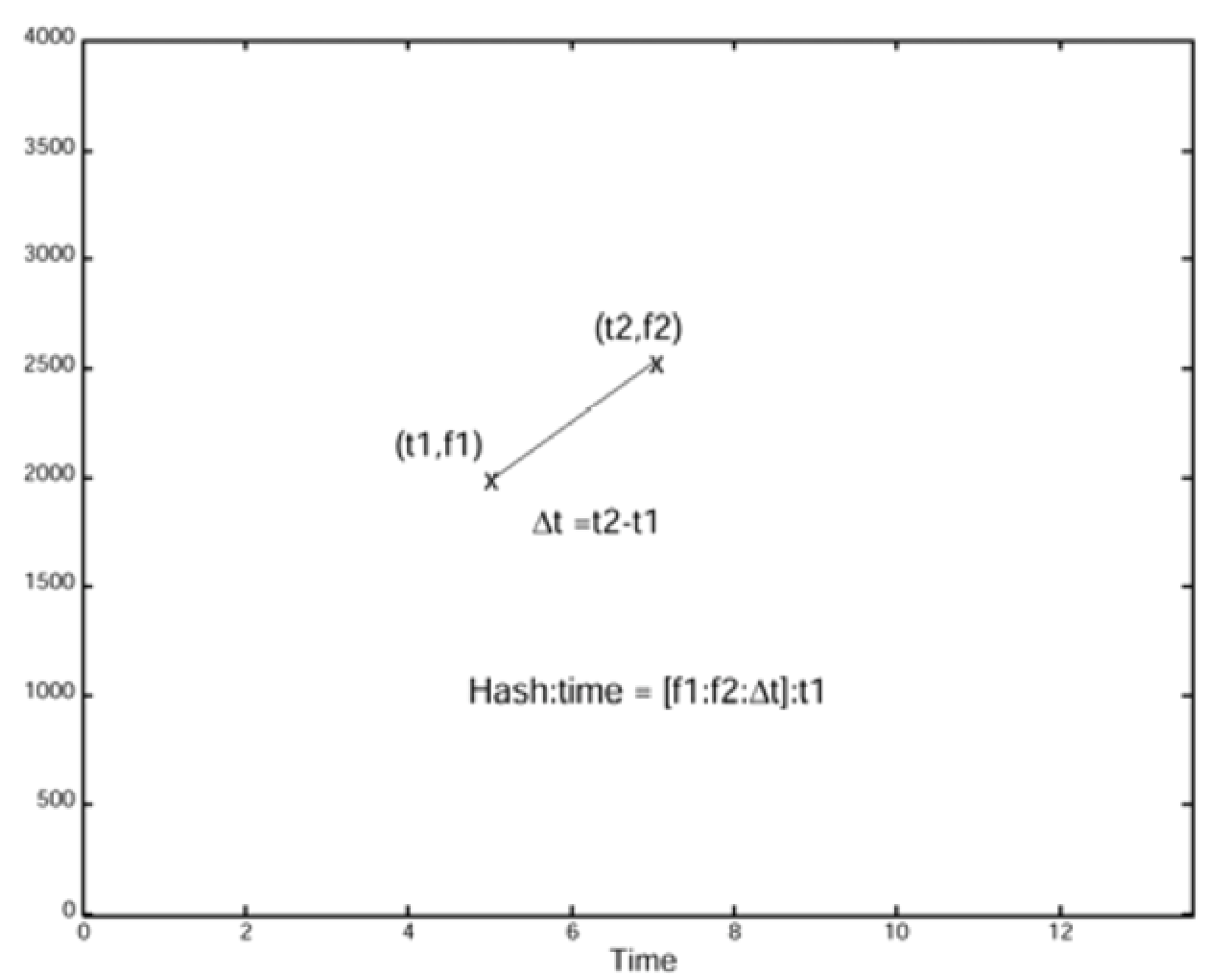
- the relations between original Anchor Point and the Nearby Peaks determine the hash, which characterize the spectrogram in time. In particular, each hash is generated by concatenating the information of time and frequency of the various points (Anchor Point and Nearby Peak) (for a total of 81 hash for every half second) [Fig.06].
At this point, every track (either the track to classify, or a track in the database) is described in time domain by the hashes found. Now, at the client side (smartphone), is sent to the server only the hashes (64bit each one) for the 10-15 seconds of the track (13-20 KB), obtaining an occupancy of bandwidth less than the full transmission of the original signal or the transmission of the transform.
On the server side, will now be compare the new hash (from the mobile device), with the previously hashes calculated for each song in the database. The comparison [Fig.07-08], carried out on the components of the hashes, it returns the recognition or not of the song recorded.
Presentation:
References:
[1] "An industrial-strength audio search algorithm" by Avery Li-chun Wang , Th Floor Block F; Shazam Entertainment, Ltd.; 2003. link
[2] "A Review of Algorithms for Audio Fingerprinting" by Pedro Cano and Eioi Batlle, Ton Kalker and Jaap Haitsma; link
[3] "Fingerprinting to identify repeated sound events in long-duration personal audio recordings" by James P. Ogle and Daniel P.W. Ellis, Columbia University; link
[4] "A Highly Robust Audio Fingerprinting System" by Jaap Haitsma and Ton Kalker; link