Audio Fingerprinting and Recognition System
Grado:
Audio Fingerprinting and Recognition System
Corso:
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Lo scopo del progetto è quello di simulare il comportamento della popolare applicazione mobile Shazam© [1]. Questo consiste nell'analisi e nell'implementazione di un sistema per il riconoscimento dei brani musicali, partendo da spezzoni audio in bassa qualità (smartphone) e in presenza di rumore di fondo.
Il riconoscimento di brani si basa sulla Fingerprint. Generalmente parlando, una fingerprint, o "impronta audio digitale", è una firma compatta, deterministica e basata sui contenuti che riassume un pezzo audio. Tale firma viene spesso usata per identificare e descrivere un pezzo audio.
In breve, le procedure necessarie per la determinazione di tale firma, sono:
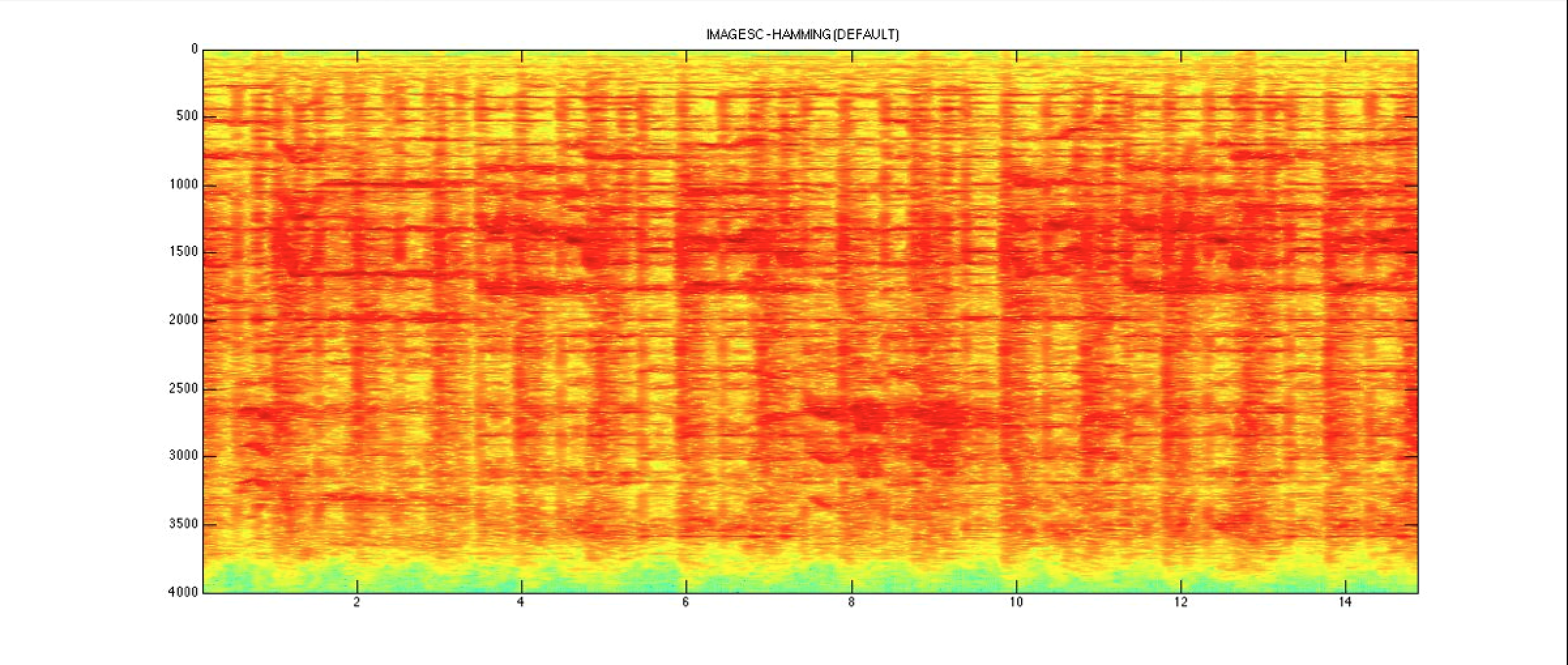
- calcolo dello spettrogramma (modulo quadro dell’intensità dei coefficienti della trasformata) [Fig.01];
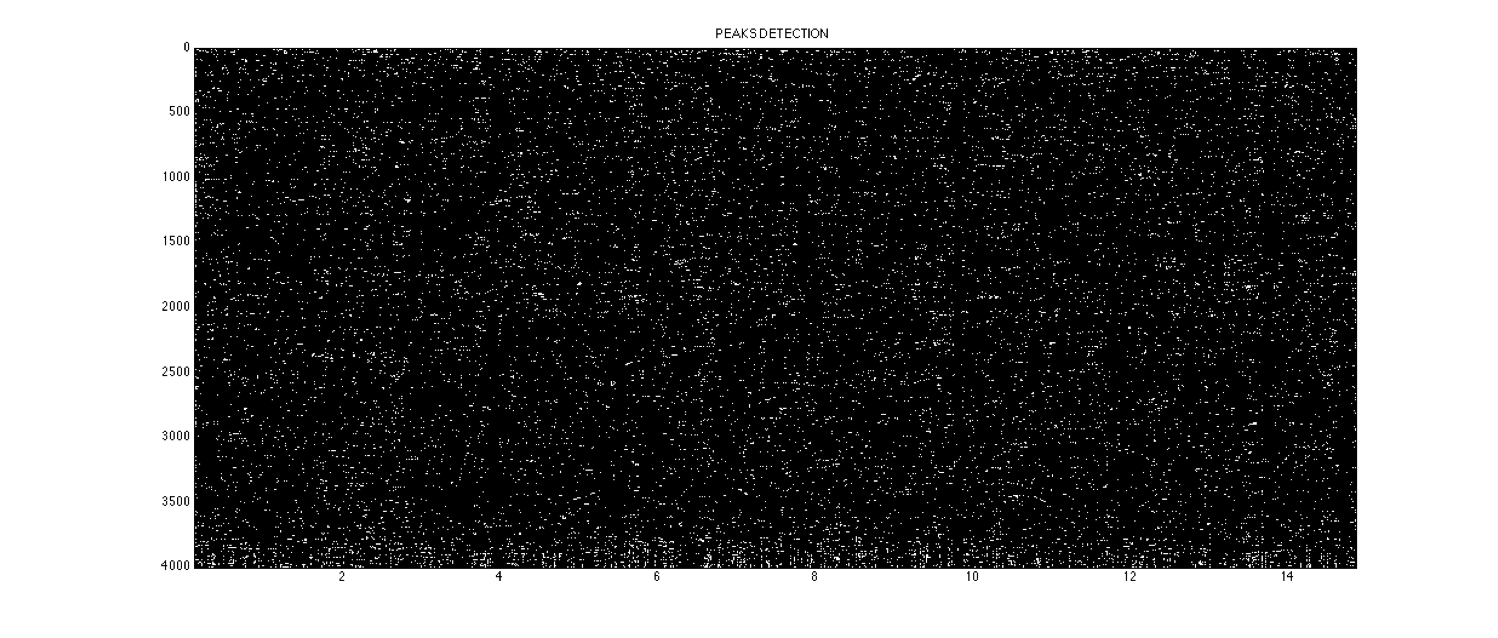
- determinazione dei massimi dello spettrogramma, guardando localmente i punti a modulo maggiore [Fig.03]
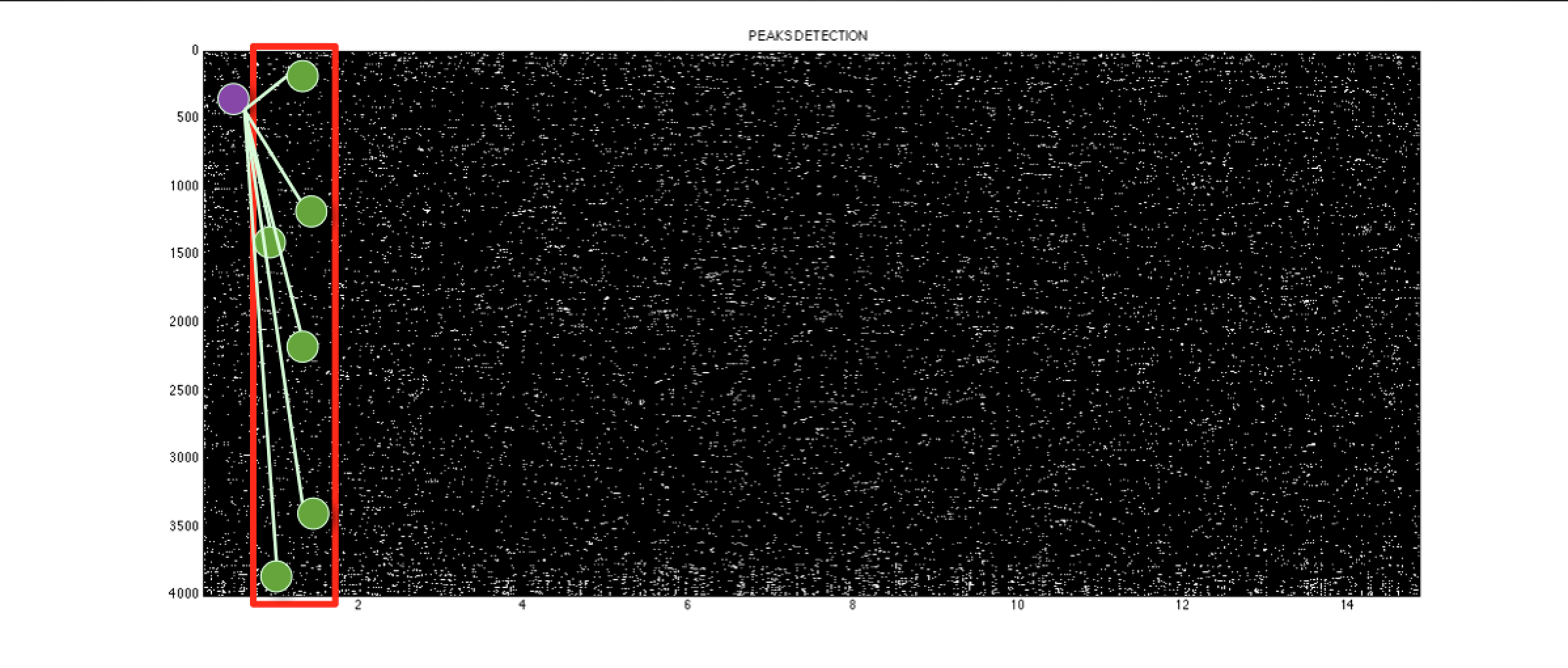
- selezione, in una regione di mezzo secondo (definito slot), dei picchi più rilevanti, chiamati Anchor Point (9 punti ogni mezzo secondo) [Fig.04];
- per ogni Anchor Point viene definita una Target Zone, una zona di ricerca, che inizia dall'Anchor Point stesso e finisce mezzo secondo dopo [Fig.05];
- nella regione così definita vengono cercati i picchi più rilevanti, chiamati Nearby Peak (altri 9 punti) [Fig.05];
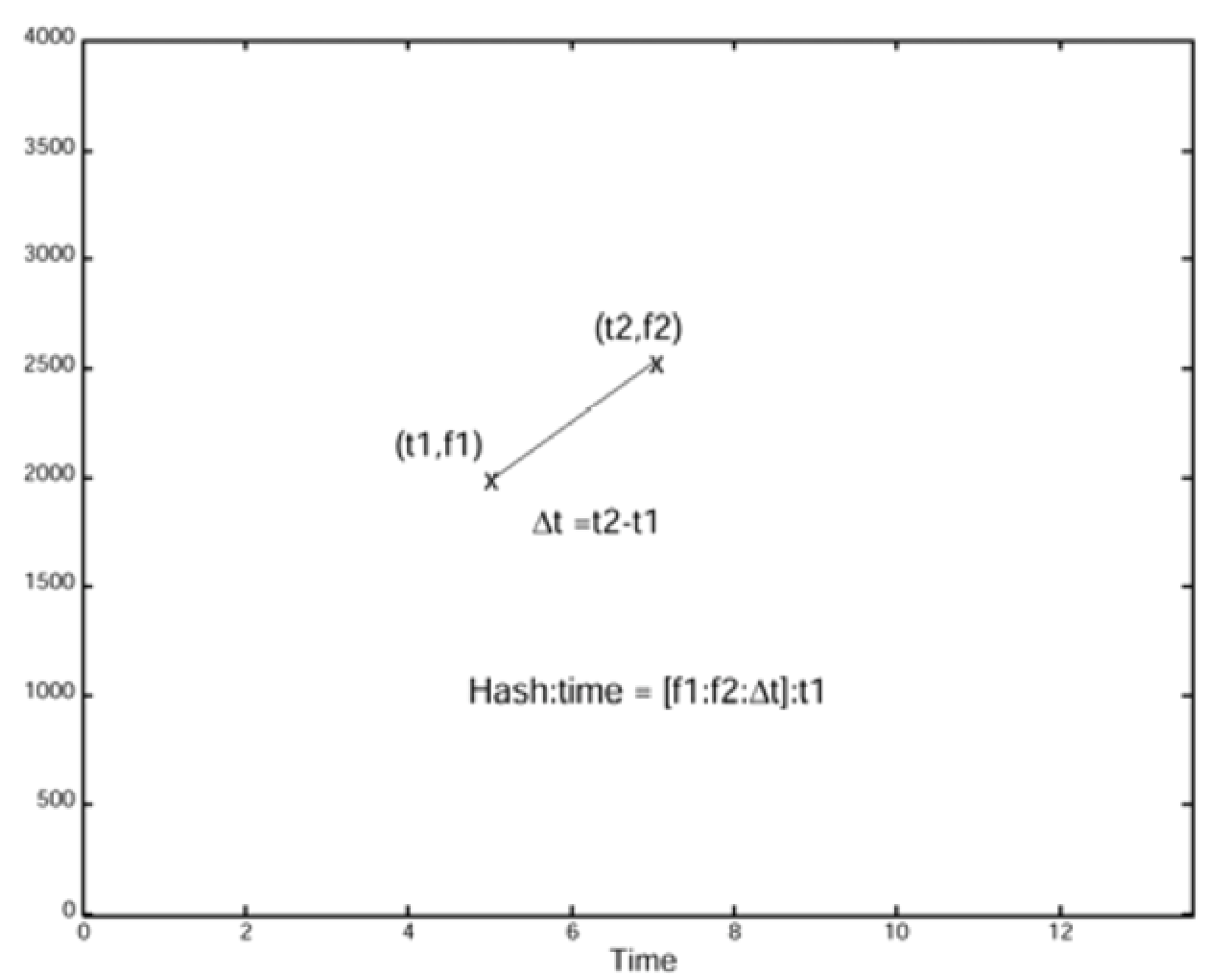
- le relazioni tra l'Anchor Point originale e i Nearby Peaks determinano degli hash, che caratterizzano lo spettrogramma nel tempo. In particolare ogni hash è generato concatenando le informazioni di frequenza e di tempo dei vari punti (Anchor Point e Nearby Peak) (per un totale di 81 hash/mezzo secondo) [Fig.06].
A questo punto, ogni traccia (sia essa la traccia da classificare, oppure una traccia nel database) viene descritta nel tempo dagli hash trovati. Ora, al lato client (smartphone), viene spedito verso il server solamente l'hash (64bit) relativo ai 10-15 secondi di traccia (13-20 KB), ottenendo un'occupazione di banda inferiore rispetto alla completa trasmissione della trasformata o del segnale originale.
A lato server, verranno ora confrontati i nuovi hash provenienti dal dispositivo mobile, con gli hash precedentemente calcolati per ogni canzone del database. Il confronto [Fig.07-08], svolto sulle componenti dell'hash, restituisce il riconoscimento o meno della canzone registrata.
Presentazione:
References:
[1] "An industrial-strength audio search algorithm" by Avery Li-chun Wang , Th Floor Block F; Shazam Entertainment, Ltd.; 2003. link
[2] "A Review of Algorithms for Audio Fingerprinting" by Pedro Cano and Eioi Batlle, Ton Kalker and Jaap Haitsma; link
[3] "Fingerprinting to identify repeated sound events in long-duration personal audio recordings" by James P. Ogle and Daniel P.W. Ellis, Columbia University; link
[4] "A Highly Robust Audio Fingerprinting System" by Jaap Haitsma and Ton Kalker; link